
The Hook: The “Black Friday” Fallacy
Most CTOs optimize their infrastructure for one specific date: Black Friday. They provision extra servers, they freeze code, and they pray.
This is a loser’s strategy.
In 2026, “Black Friday” is no longer a date on the calendar; it is a random Tuesday morning when a shopping agent discovers your pricing error or a viral TikTok trend hits your SKU.
If your scaling strategy relies on manual intervention—or worse, a phone call to your hosting provider—you have already lost the sale. The market has moved from “Planned Peaks” to “Always-On Volatility.” You don’t need a bigger server; you need a biological immune system.
The Market Context: The Speed of “Machine Commerce”
Why is legacy scaling failing right now?
- The Sub-100ms Standard: In 2024, a 2-second load time was acceptable. In 2026, with 5G widespread and AI agents executing trades, anything over 100ms is considered downtime. If your API is slow, the shopping bot skips you.
- The Write-Heavy Shift: E-commerce used to be “Read Heavy” (people browsing). Now it is “Write Heavy” (agents adding to cart, checking distinct shipping permutations, and pinging inventory APIs). Your caching layer is useless if the requests are dynamic state changes.
- The “Flash” Normalization: Social commerce drops are instant. You can go from 0 to 50,000 concurrents in 6 seconds. Monoliths cannot autoscale that fast; they just break..
The Core Analysis: The “Anti-Fragile” Architecture
Stop building “robust” systems (that resist breaking). Build “anti-fragile” systems (that get stronger under stress).
1. The “Edge-First” Logic Layer
Your centralized server in Virginia is too far away.
- The Shift: Move your checkout logic and personalization to the Edge (e.g., Cloudflare Workers, Vercel Edge).
- Why: When a user in Tokyo hits “Buy,” the tax calculation and inventory check should happen in a Tokyo data center, not round-tripped to the US. This reduces latency by 400ms—which equates to a 6% conversion lift.
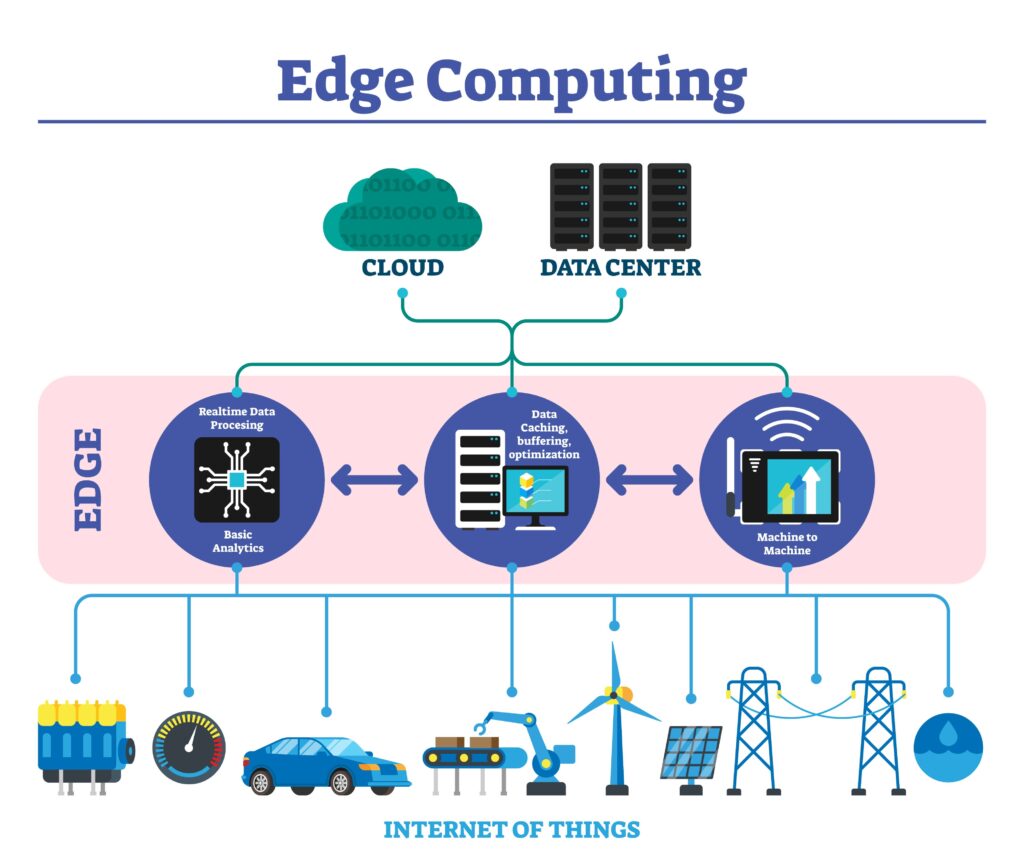
2. Database Sharding: The “Write” Solution
Your database is your bottleneck. You can replicate it for reads, but you can’t replicate it for writes (orders) without locking issues.
- The Strategy: Implement Horizontal Sharding by Customer ID or Region.
- The Execution: US-East customers live in Shard A; EU customers live in Shard B. If Shard A goes down under load, Shard B keeps processing orders. You compartmentalize the failure radius. A total outage becomes a partial inconvenience.
3. The “Queue-Based” Load Leveling
Stop letting users hit your database directly.
- The Problem: 10,000 users hitting “Checkout” simultaneously = Database Lock.
- The Strategy: Decouple the “Buy” button from the “Order Created” event. Use a high-throughput message queue (like Kafka or Amazon SQS).
- The Flow: The user clicks “Buy” -> The UI says “Processing” instantly -> The request enters a Queue -> A worker processes it asynchronously. This ensures your database processes orders at a constant, safe rate, even if the input spikes 1000x.
Strategic Takeaway: The “Chaos” Mandate
What is your move for tomorrow?
Stop trusting your “Uptime” dashboard.
If it says 99.9%, it’s lying about the 0.1% that matters (the peak).
Execute a “Chaos Engineering” Game Day:
- The “Kill Switch” Test: randomly terminate a production pod or database replica during business hours. (Netflix has done this for a decade; why aren’t you?)
- The “Agent Storm”: Simulate 50,000 concurrent AI agents hitting your “Add to Cart” endpoint, not your homepage.
- The “Graceful Degradation” Audit: If your inventory service fails, does the whole site 404? Or does it fall back to a “Pre-Order” mode?
In 2026, your infrastructure is not a utility; it is your primary competitive advantage. If you can’t scale, you can’t sell.